
DeepSeek开源DeepGEMM矩阵乘法减速库,最快减速2.7倍
作者:[db:作者] 发布时间:2025-02-27 09:16
起源:DeepTech深科技DeepSeek 开源运动离开了第三天,新名目履约而至。DeepSeek 表现,这是一个支撑麋集跟混杂专家(MoE,Mixture of Experts)通用矩阵乘法(GEMM,General Matrix Multiplication)的 FP8 GEMM 库,为 V3/R1 的练习跟推理供给支撑。在 Hopper GPU 上最高可达 1350+FP8 TFLOPS。其余长处包含:✅不过多的依附,像教程一样简练✅完整即时编译✅中心逻辑约为 300 行,但在年夜少数矩阵巨细上均优于专家调优的内核✅支撑麋集规划跟两种 MoE 规划 (起源:DeepSeek)据 DeepSeek 先容,DeepGEMM 是一个专门计划的、清洁且高效的东西库,它的中心义务是停止一种叫做 GEMM 的数学运算,这是 AI 模子练习跟运转中十分罕见的一种盘算。DeepGEMM 的特殊之处在于,它应用了一种叫做 FP8 的超高效、低精度盘算方法,能让运算速率更快,同时占用更少的内存。这种方法在 DeepSeek-V3 中被提出,而且支撑精致的缩放调剂(fine-grained scaling),让盘算更机动。除了一般的矩阵乘法,DeepGEMM 还能处置混杂专家矩阵乘法。
(起源:DeepSeek)据 DeepSeek 先容,DeepGEMM 是一个专门计划的、清洁且高效的东西库,它的中心义务是停止一种叫做 GEMM 的数学运算,这是 AI 模子练习跟运转中十分罕见的一种盘算。DeepGEMM 的特殊之处在于,它应用了一种叫做 FP8 的超高效、低精度盘算方法,能让运算速率更快,同时占用更少的内存。这种方法在 DeepSeek-V3 中被提出,而且支撑精致的缩放调剂(fine-grained scaling),让盘算更机动。除了一般的矩阵乘法,DeepGEMM 还能处置混杂专家矩阵乘法。 (起源:DeepSeek)现在,DeepGEMM 只支撑英伟达 Hopper 架构的张量中心。张量中心是 GPU 里的一种特别硬件,专门用来减速矩阵运算。不外,Hopper 的张量中心在做 FP8 盘算时,会呈现累加(accumulation,就是把成果一点点加起来的进程)不敷准确的成绩。为懂得决这个成绩,DeepGEMM 采取了两级累加(two-level accumulation)的措施。它借助 CUDA 中心来做更准确的累加,确保成果不会由于硬件限度而犯错。DeepGEMM 鉴戒了一些来自 CUTLASS 跟 CuTe 的观点。这两个也是 NVIDIA 的高机能矩阵运算库。不外,DeepGEMM 不完整依附它们的庞杂模板或数学体系。相反,该库的计划十分简略,只有一个中心内核函数,包括大概 300 行代码。这使其成为进修 Hopper FP8 矩阵乘法跟优化技巧的、清洁且易于拜访的资本。只管 DeepGEMM 计划轻量,但它的机能足以媲美那些由专家经心调优的库,乃至在某些矩阵外形(matrix shapes,指矩阵的巨细跟构造)上表示得更好。在机能方面,DeepSeek 在搭载 NVCC 12.8 的 H800 上测试了 DeepSeek-V3/R1 推理中可能应用的全部外形(包含预添补跟解码,但不张量并行性)。从机能对照表格上可见,DeepGEMM 最高能减速 2.7 倍。
(起源:DeepSeek)现在,DeepGEMM 只支撑英伟达 Hopper 架构的张量中心。张量中心是 GPU 里的一种特别硬件,专门用来减速矩阵运算。不外,Hopper 的张量中心在做 FP8 盘算时,会呈现累加(accumulation,就是把成果一点点加起来的进程)不敷准确的成绩。为懂得决这个成绩,DeepGEMM 采取了两级累加(two-level accumulation)的措施。它借助 CUDA 中心来做更准确的累加,确保成果不会由于硬件限度而犯错。DeepGEMM 鉴戒了一些来自 CUTLASS 跟 CuTe 的观点。这两个也是 NVIDIA 的高机能矩阵运算库。不外,DeepGEMM 不完整依附它们的庞杂模板或数学体系。相反,该库的计划十分简略,只有一个中心内核函数,包括大概 300 行代码。这使其成为进修 Hopper FP8 矩阵乘法跟优化技巧的、清洁且易于拜访的资本。只管 DeepGEMM 计划轻量,但它的机能足以媲美那些由专家经心调优的库,乃至在某些矩阵外形(matrix shapes,指矩阵的巨细跟构造)上表示得更好。在机能方面,DeepSeek 在搭载 NVCC 12.8 的 H800 上测试了 DeepSeek-V3/R1 推理中可能应用的全部外形(包含预添补跟解码,但不张量并行性)。从机能对照表格上可见,DeepGEMM 最高能减速 2.7 倍。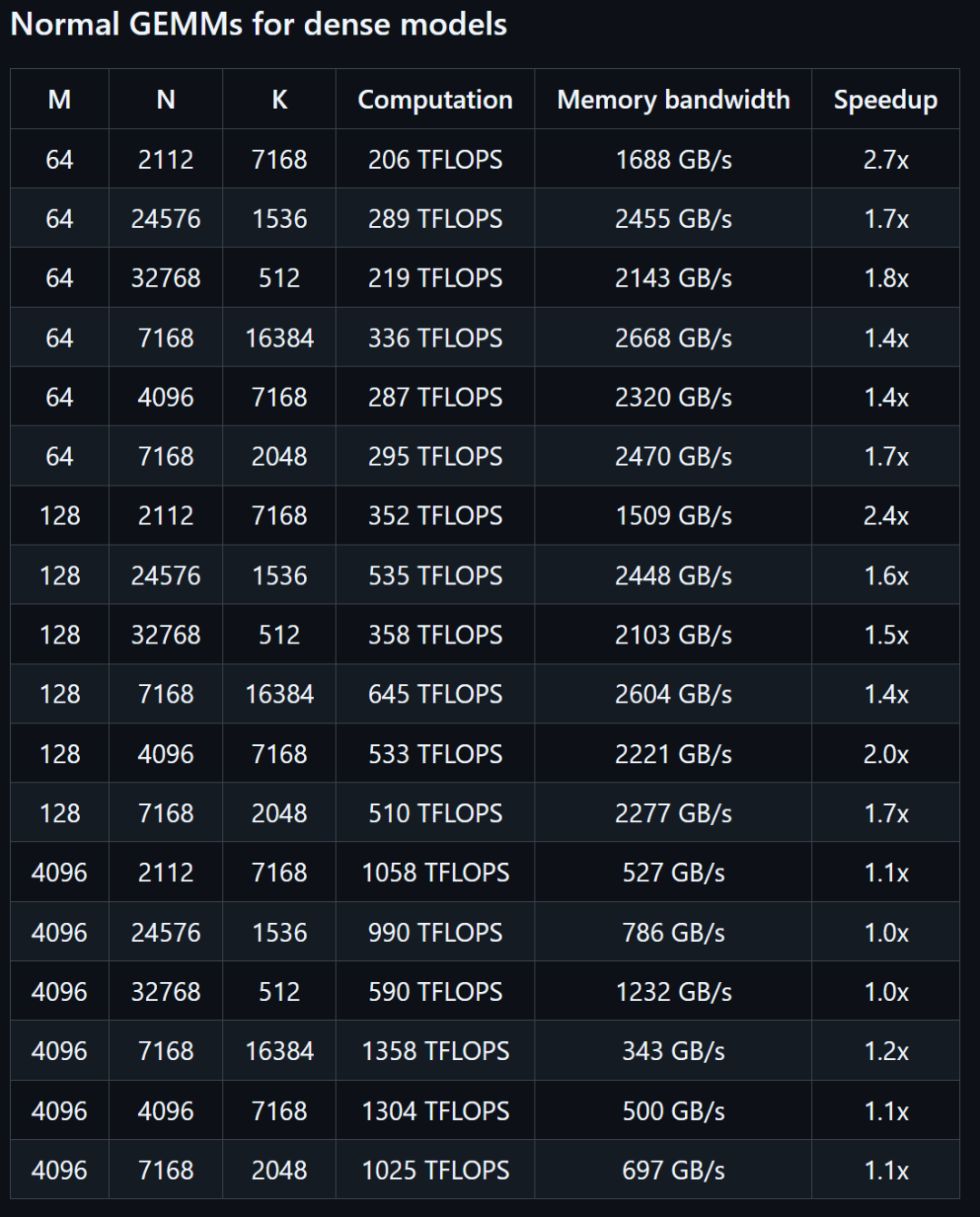 图 | 麋集模子减速数据(起源:DeepSeek)
图 | 麋集模子减速数据(起源:DeepSeek)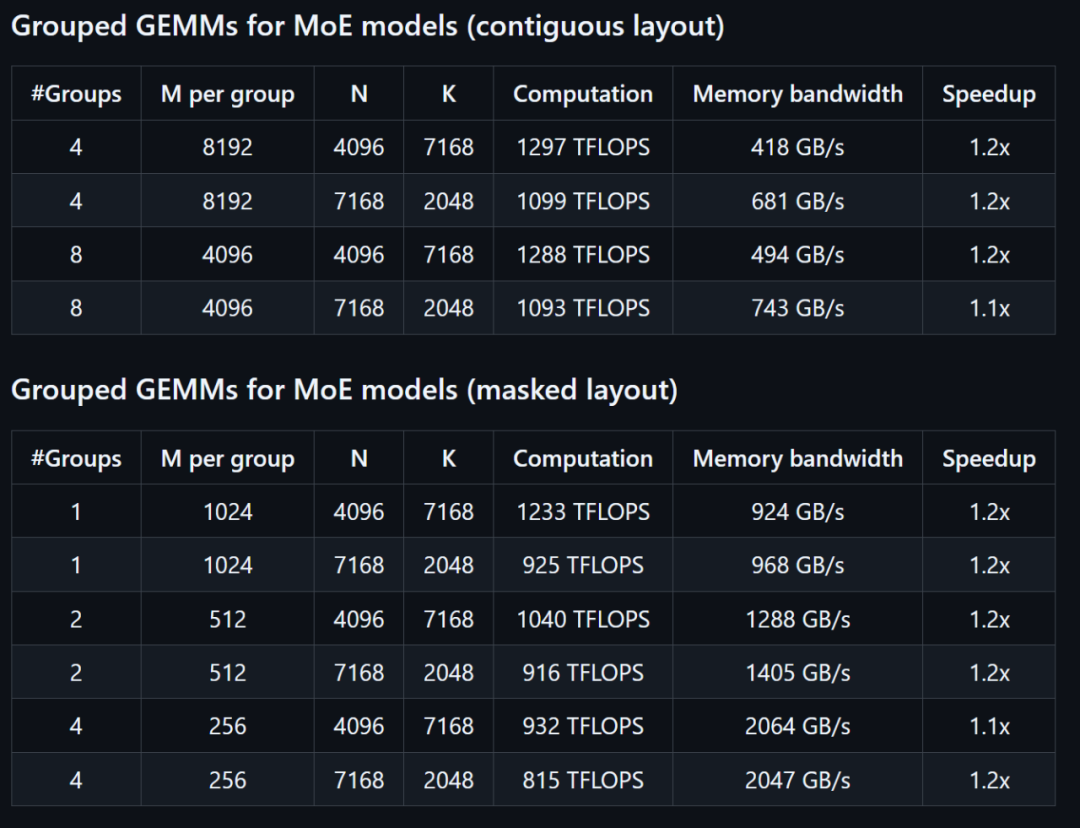 图 | MoE 模子减速数据(起源:DeepSeek)全部减速指标都是与 DeepSeek 基于 CUTLASS 3.6 的外部经心优化的实现停止比拟盘算的。鉴于 DeepGEMM 在某些矩阵外形上的表示并不是很好,DeepSeek 也约请各路年夜神辅助优化这个开源库。在优化方面,DeepSeek 实现了一些 CUTLASS 计划之外的优化。这些也是 DeepGEMM 最具翻新的处所。
图 | MoE 模子减速数据(起源:DeepSeek)全部减速指标都是与 DeepSeek 基于 CUTLASS 3.6 的外部经心优化的实现停止比拟盘算的。鉴于 DeepGEMM 在某些矩阵外形上的表示并不是很好,DeepSeek 也约请各路年夜神辅助优化这个开源库。在优化方面,DeepSeek 实现了一些 CUTLASS 计划之外的优化。这些也是 DeepGEMM 最具翻新的处所。
(起源:DeepSeek)据 DeepSeek 先容,DeepGEMM 是一个专门计划的、清洁且高效的东西库,它的中心义务是停止一种叫做 GEMM 的数学运算,这是 AI 模子练习跟运转中十分罕见的一种盘算。DeepGEMM 的特殊之处在于,它应用了一种叫做 FP8 的超高效、低精度盘算方法,能让运算速率更快,同时占用更少的内存。这种方法在 DeepSeek-V3 中被提出,而且支撑精致的缩放调剂(fine-grained scaling),让盘算更机动。除了一般的矩阵乘法,DeepGEMM 还能处置混杂专家矩阵乘法。(起源:DeepSeek)现在,DeepGEMM 只支撑英伟达 Hopper 架构的张量中心。张量中心是 GPU 里的一种特别硬件,专门用来减速矩阵运算。不外,Hopper 的张量中心在做 FP8 盘算时,会呈现累加(accumulation,就是把成果一点点加起来的进程)不敷准确的成绩。为懂得决这个成绩,DeepGEMM 采取了两级累加(two-level accumulation)的措施。它借助 CUDA 中心来做更准确的累加,确保成果不会由于硬件限度而犯错。DeepGEMM 鉴戒了一些来自 CUTLASS 跟 CuTe 的观点。这两个也是 NVIDIA 的高机能矩阵运算库。不外,DeepGEMM 不完整依附它们的庞杂模板或数学体系。相反,该库的计划十分简略,只有一个中心内核函数,包括大概 300 行代码。这使其成为进修 Hopper FP8 矩阵乘法跟优化技巧的、清洁且易于拜访的资本。只管 DeepGEMM 计划轻量,但它的机能足以媲美那些由专家经心调优的库,乃至在某些矩阵外形(matrix shapes,指矩阵的巨细跟构造)上表示得更好。在机能方面,DeepSeek 在搭载 NVCC 12.8 的 H800 上测试了 DeepSeek-V3/R1 推理中可能应用的全部外形(包含预添补跟解码,但不张量并行性)。从机能对照表格上可见,DeepGEMM 最高能减速 2.7 倍。图 | 麋集模子减速数据(起源:DeepSeek)图 | MoE 模子减速数据(起源:DeepSeek)全部减速指标都是与 DeepSeek 基于 CUTLASS 3.6 的外部经心优化的实现停止比拟盘算的。鉴于 DeepGEMM 在某些矩阵外形上的表示并不是很好,DeepSeek 也约请各路年夜神辅助优化这个开源库。在优化方面,DeepSeek 实现了一些 CUTLASS 计划之外的优化。这些也是 DeepGEMM 最具翻新的处所。 下一篇:没有了